

Scientists identify four personality types, Chances are you’ve had it.
People love taking online quizzes; just ask Buzzfeed and Facebook. A new study has sifted through some of the largest online data sets of personality quizzes and identified four distinct “types” therein. The new methodology used for this study—described in detail in a new paper in Nature Human Behavior—is rigorous and replicable, which could help move personality typing analysis out of the dubious self-help section in your local bookstore and into serious scientific journals.
Frankly, personality “type” is not the ideal nomenclature here; personality “clusters” might be more accurate. Paper co-author William Revelle (Northwestern University) bristles a bit at the very notion of distinct personality types, like those espoused by the hugely popular Myers-Briggs Type Indicator. Revelle is an adamant “anti-fan” of the Myers-Briggs, and he is not alone. Most scientists who study personality prefer to think of it as a set of continuous dimensions, in which people shift where they fall on the spectrum of various traits as they mature.
What’s new here is the identification of four dominant clusters in the overall distribution of traits. Revelle prefers to think of them as “lumps in the batter” and suggests that a good analogy would be how people tend to concentrate in cities in the United States.
Divide the country into four regions—north, south, east, and west—and then look at how the population density is distributed. You will likely find the highest concentration of people living in dense cities like New York, Chicago, Los Angeles, or Houston. “But to describe everyone as living in one of those four cities is a mistake,” he says. Similarly, “What we’re describing is the likelihood of being at certain parts of that distribution; we’re not saying that everyone is in one of those four categories.”
The Northwestern researchers used publicly available data from online quizzes taken by 1.5 million people around the world. That data was then plotted in accordance with the so-called Big Five basic personality traits: neuroticism, extraversion, openness, agreeableness, and conscientiousness. The Big Five is currently the professional standard for social psychologists who study personality. (Here’s a good summary of what each of those traits means to psychologists.) They then applied their algorithms to the resulting dataset.
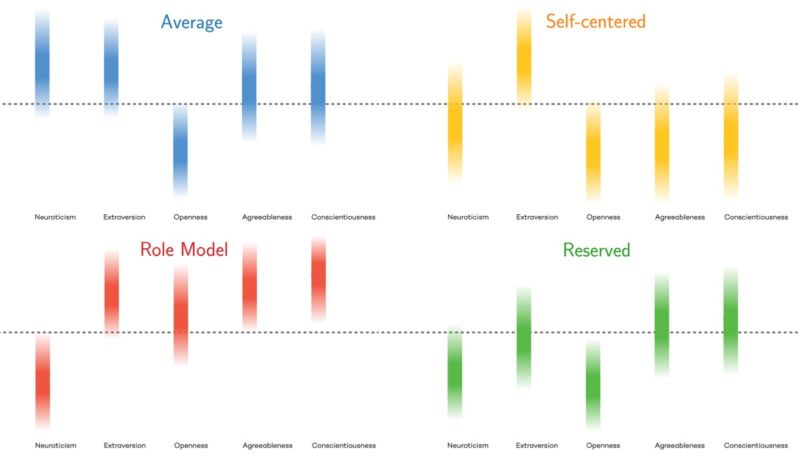
The four “types”
Revelle admits that when his Northwestern colleague and co-author Luis Amaral came to him with the initial findings using traditional clustering algorithms, he had found 16 distinct clusters. Revelle was instantly skeptical: “That was ridiculous,” he says. He didn’t think there were any types at all lurking in the data, and challenged Amaral and another co-author, Martin Gerlach, to better refine their analysis.
“These statistical learning algorithms do not automatically produce the right answer,” says Revelle. “You need to then compare it to random solutions.” That second step made all the difference, by imposing extra constraints to winnow down the results. The researchers ended up with four distinct personality clusters:
Average: These people score high in neuroticism and extraversion, but score low in openness. It is the most typical category, with women being more likely than men to fit into it.
Reserved: This type of person is stable emotionally without being especially open or neurotic. They tend to score lower on extraversion but tend to be somewhat agreeable and conscientious.
Role Models: These people score high in every trait except neuroticism, and the likelihood that someone fits into this category increases dramatically as they age. “These are people who are dependable and open to new ideas,” says Amaral. “These are good people to be in charge of things.” Women are more likely than men to be role models.
Self-Centered: These people score very high in extraversion, but score low in openness, agreeableness, and conscientiousness. Most teenage boys would fall into this category, according to Revelle, before (hopefully) maturing out of it. The number of people who fall into this category decreases dramatically with age.
The team used one data set on the first analysis and then replicated the same result on two other independent data sets, meaning their methodology is replicable—at least on similarly large datasets, which are much more common today, thanks to the Internet and rise of open access. “A study with a dataset this large would not have been possible before the web,” says Amaral.
")
")

")
")





")